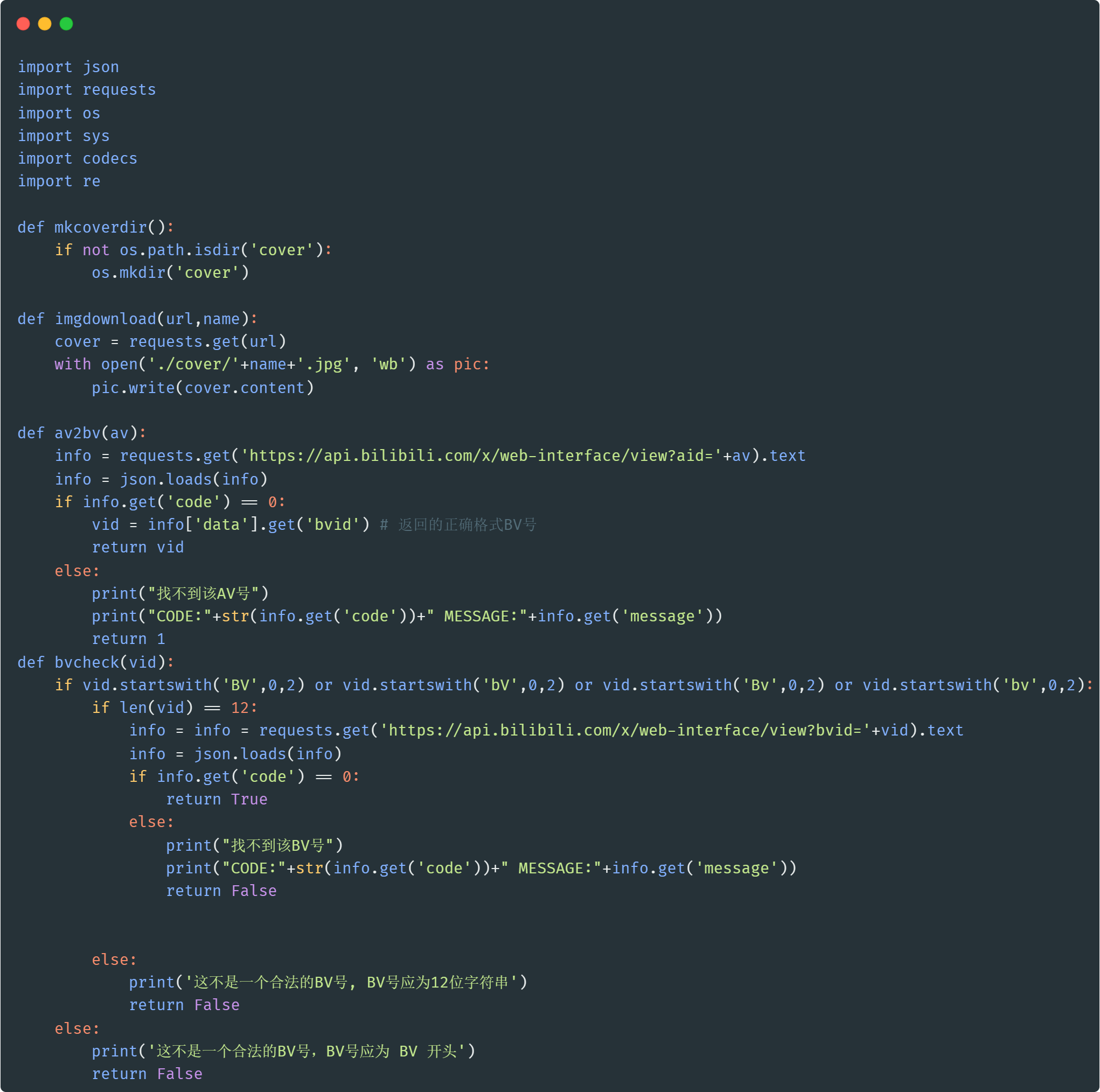
defimgdownload(url,name): cover = requests.get(url) withopen('./cover/'+name+'.jpg', 'wb') as pic: pic.write(cover.content)
defav2bv(av): info = requests.get('https://api.bilibili.com/x/web-interface/view?aid='+av).text info = json.loads(info) if info.get('code') == 0: vid = info['data'].get('bvid') 返回的正确格式BV号 return vid else: print("找不到该AV号") print("CODE:"+str(info.get('code'))+" MESSAGE:"+info.get('message')) return1 defbvcheck(vid): if vid.startswith('BV',0,2) or vid.startswith('bV',0,2) or vid.startswith('Bv',0,2) or vid.startswith('bv',0,2): iflen(vid) == 12: info = info = requests.get('https://api.bilibili.com/x/web-interface/view?bvid='+vid).text info = json.loads(info) if info.get('code') == 0: returnTrue else: print("找不到该BV号") print("CODE:"+str(info.get('code'))+" MESSAGE:"+info.get('message')) returnFalse
if status == '1': vid = input('AV号:') vid = re.sub('av', '', vid, flags=re.IGNORECASE) if vid.isdigit(): vid = av2bv(vid) if vid == 1: valid = False else: print('这不是一个合法的AV号') valid = False
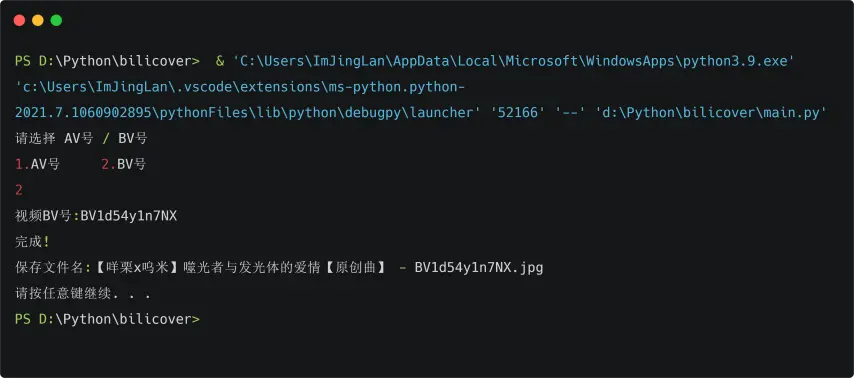
if status == '2': vid = input('视频BV号:')#获取视频BV号
if status == '1'or status == '2': if valid: if bvcheck(vid): info = requests.get('https://api.bilibili.com/x/web-interface/view?bvid='+vid).text info = json.loads(info) bvid = info['data'].get('bvid') 返回的正确格式BV号 cover = info['data'].get('pic') 封面地址d title = info['data'].get('title') 视频标题 if status == '1': vid = "av"+str(info['data'].get('aid')) #返回的正确格式AV号 if status == '2': vid = info['data'].get('bvid') 返回的正确格式BV号 print(title+' - '+bvid+": "+cover) print('完成!') 提示一下 print("保存文件名:"+title+' - '+vid+".jpg") imgdownload(cover,title+' - '+vid) 下载 else: print("这不是一个合法的状态码")
主程序 if __name__ == "__main__": main() os.system('pause')
自己加了 AV 号与 BV 号的判断,如果是 AV 号就把 AV 转换成 BV 再用 BV 手法去找封面